













公有云大模型服务性能提升显著 中国信通院发布2025年度监测结果
2026-02-11 15:57
来源:中国网




随着大模型技术的迅速迭代,以及模型即服务(Model as a Service,MaaS)产业的快速发展,国内外越来越多的MaaS平台厂商通过公有云API方式供给大模型服务,助推大模型普惠化规模化落地。与此同时,行业用户普遍缺乏对大模型服务性能的直观量化判断依据,面临选型困难、服务质量难以对标等现实问题。近日,中国信息通信研究院(以下简称“中国信通院”)联合人工智能大模型及软硬件评测工业和信息化部重点实验室(以下简称实验室)、中国人工智能产业发展联盟(AIIA)模型服务(MaaS)工作组,共同发布了2025年度公有云大模型服务性能监测结果。此次监测旨在科学、系统、客观地衡量公有云大模型服务性能水平,推动大模型技术的普惠化与规模化应用。
大模型服务性能持续优化用户体验显著提升
本次监测周期为2025年全年,重点监测了42个原厂大模型服务,其中国内38个,国外4个。监测结果显示,大模型服务性能在多个维度上均实现了显著提升。
1.大部分大模型服务的调用成功率已趋于稳定,成功率逼近100%。国内方面,3月份以来调用成功率均超过99%,12月份各模型平均调用成功率达到99.9%,其中68%的大模型达到100%,大模型服务的稳定性持续向好。被监测的4款国外大模型服务调用成功率均达到100%。
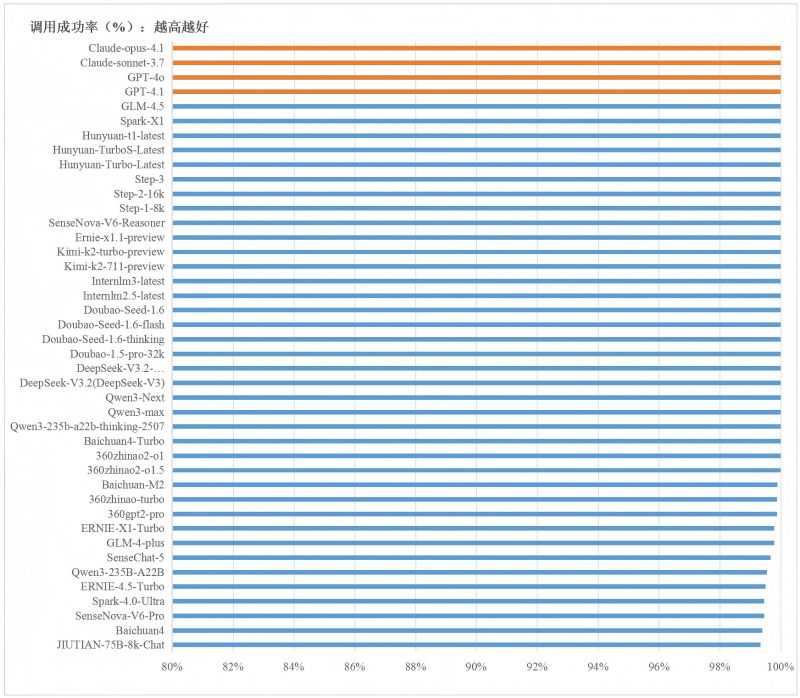
图 1各原厂大模型12月份调用成功率平均值
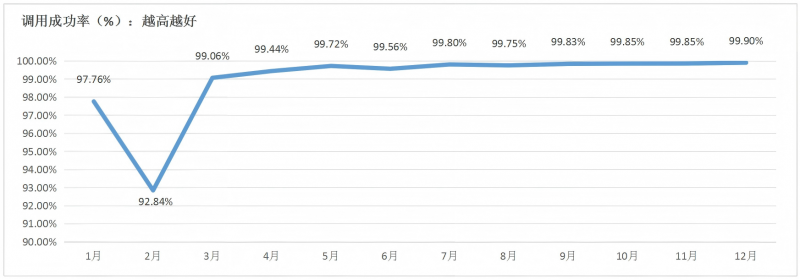
图 2被监测的所有国内大模型每月调用成功率平均值
2.多数大模型服务的每秒输出字符数(TPS)呈现上升趋势,第四季度最为明显。国内方面,各模型整体TPS平均值呈现逐月上升的趋势,2025年9月至12月TPS快速上升,月平均涨幅达8%。第四季度TPS增长明显,12月份相比2月份提升约67%,各模型的平均TPS达到50.5(个/秒),相比8月份提升44%。国外模型GPT和Claude的TPS均值达到51.35(个/秒)。
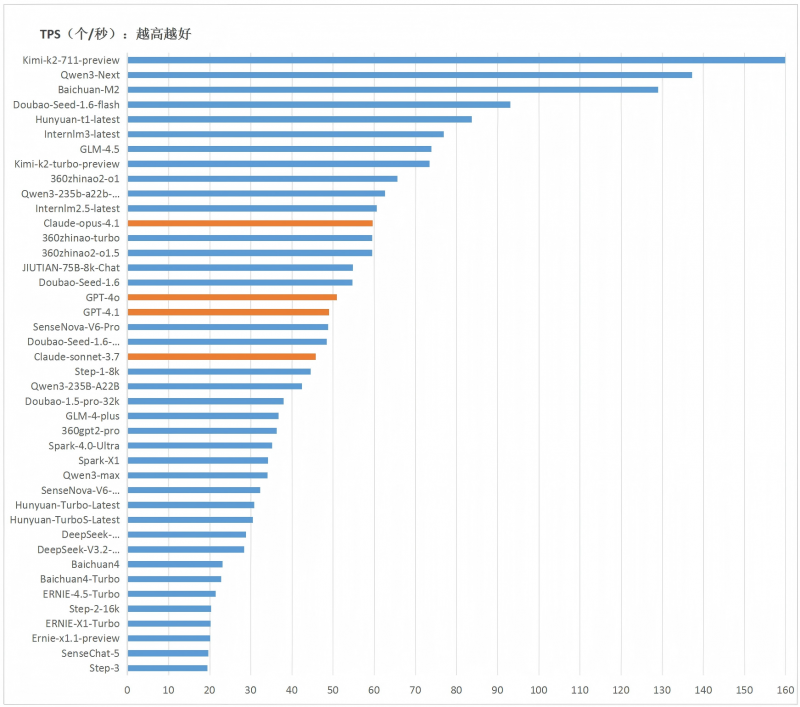
图 3各原厂大模型12月份TPS平均值
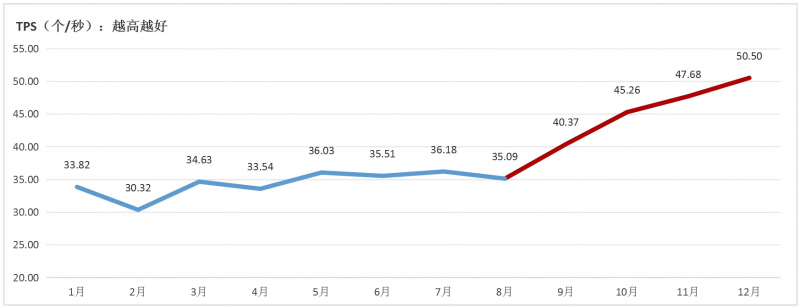
图 4每月所有被监测国内大模型TPS平均值
3.多数大模型服务的首字符时延(TTFT)各月平均数据均低于1秒,第四季度下降明显。国内方面,12月份76%的大模型TTFT数值已达到1秒以下,29%的大模型达到0.5秒以下,中位数为0.58秒,明显低于前三个季度的数值。国外模型GPT和Claude模型的TTFT均低于0.5秒。
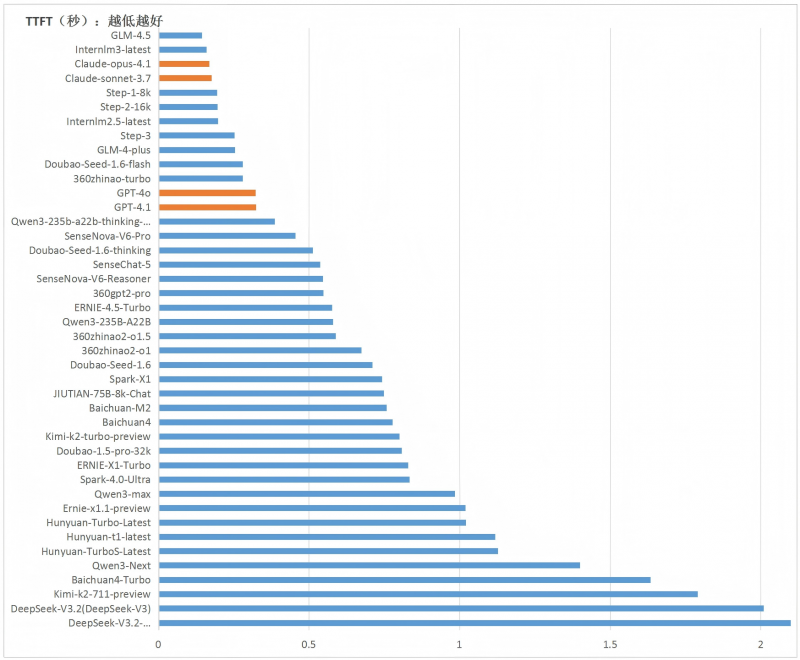
图 5各原厂大模型12月份TTFT平均值
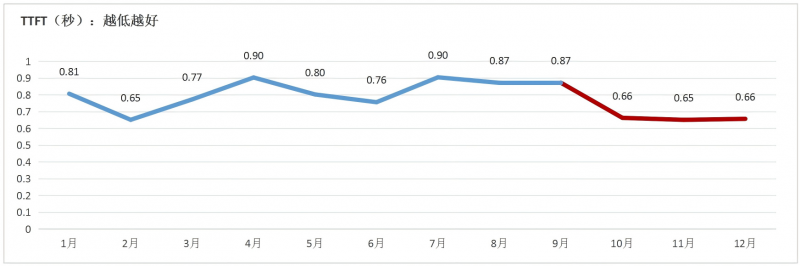
图 6被监测所有国内大模型每月的TTFT平均值
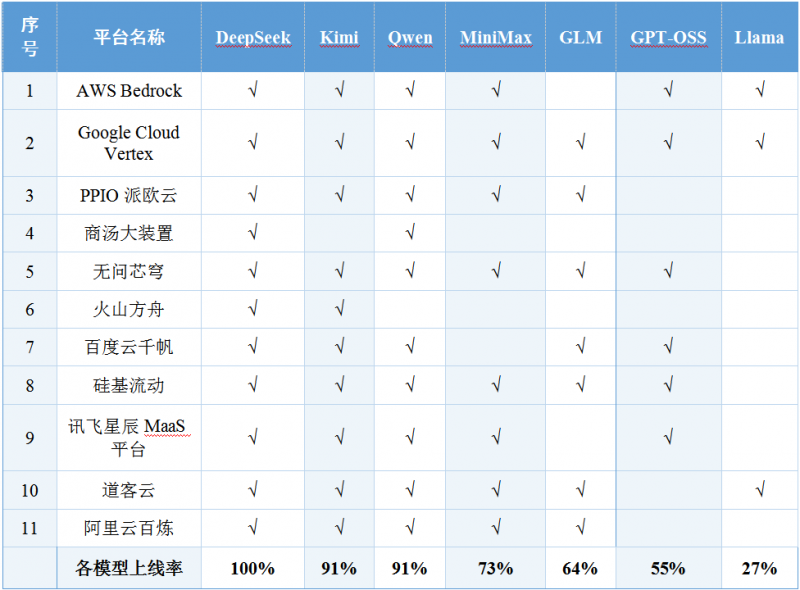
4.国产开源大模型成为全球开发者首选的受欢迎程度日益提升。
根据开源大模型在被监测MaaS平台中的上线率显示,DeepSeek上线率达到100%,其次为Kimi、Qwen、MiniMax、GLM、GPT、Llama,上线率分别为91%、91%、73%、64%、55%、27%。
表 1典型开源大模型在各MaaS平台的上线率统计
5.大模型服务调用价格逐步下降,国外模型价格仍远高于国内。
随着技术的不断成熟和市场竞争的加剧,大模型服务调用价格逐步下降。国内多数模型价格已低于10元/百万Token,而国外模型价格仍远高于国内,如GPT 5.2和Claude Opus 4.5的价格仍分别高达33.7元/百万Token和70元/百万Token。
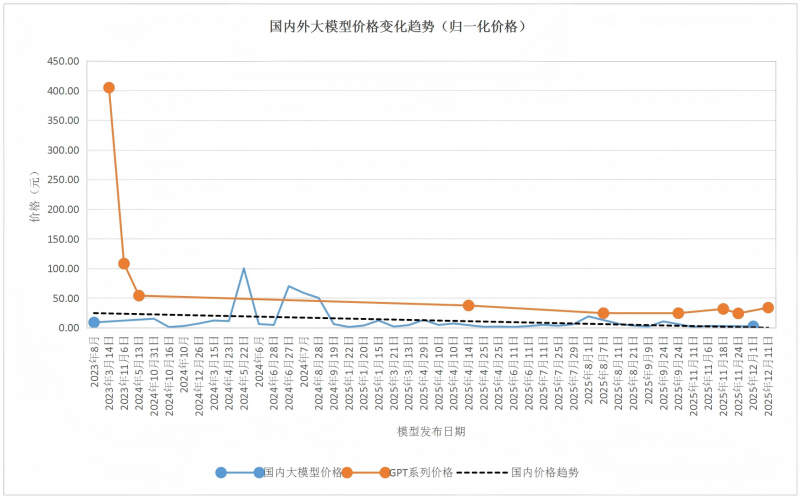
图 7原厂大模型发布时归一化价格趋势图
6.更长的模型上下文长度成为新的发展趋势。
被监测的模型中,128K和256K上下文占比较高,共计约为47.6%,相比上半年提升了10个百分点,显示出市场对长上下文大模型需求的增长。
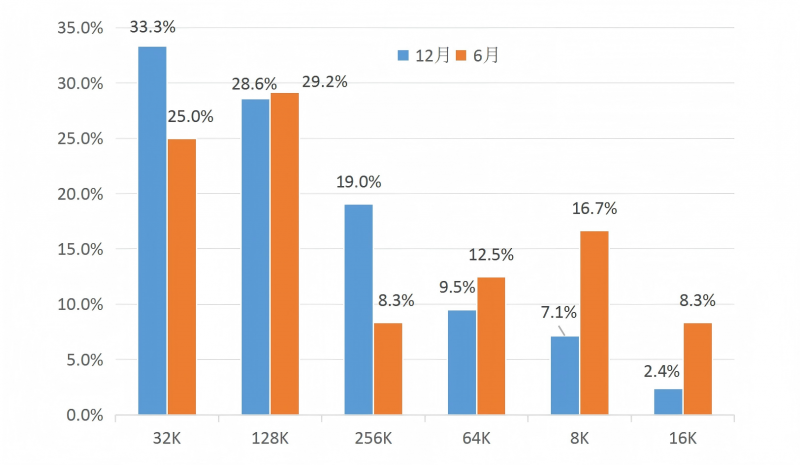
图 8原厂大模型上下文长度占比
MaaS平台工程化能力不断迭代,系统稳定性持续提升
本次监测是指对纳入监测范围的13个国内外(国内11个,国外2个)MaaS平台所提供的DeepSeek-R1和DeepSeek-V3(含V3.1和V3.2)相关版本的API服务进行监测,监测周期为2025年2月至12月。
1.公有云MaaS平台供给的DeepSeek模型服务自3月份以来呈现持续优化趋势。DeepSeek在各MaaS平台上的TTFT平均值,R1由2月份的3.07秒降低至9月份的1.02秒,V3由2月份的2.4秒降低至12月份的1.35秒;TPS平均值R1由2月份的17.86(个/秒)提升至12月份的37.29(个/秒),V3由19.55(个/秒)提升至33.27(个/秒)。国外方面,亚马逊和谷歌云TTFT均可达到0.8秒上下,亚马逊的TPS达到96.19(个/秒),谷歌云的TPS达到113.63(个/秒)。
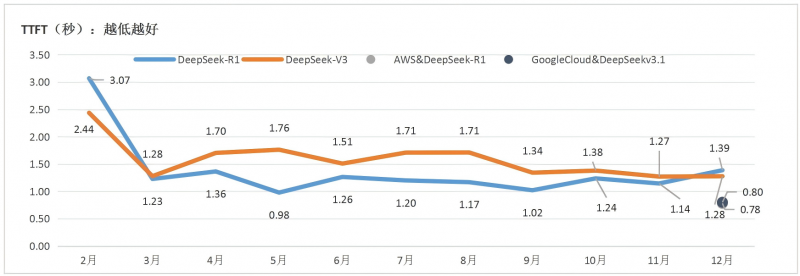
图 9 DeepSeek每月所有平台TTFT平均值
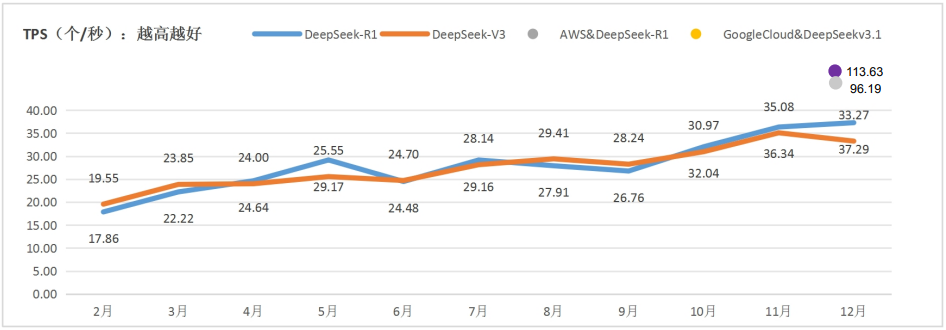
图 10 DeepSeek每月所有平台TPS平均值
2.公有云MaaS平台的系统稳定性大幅提升,当前较为平稳。各平台供给的DeepSeek模型服务调用成功率,自3月份以来均大于99%,R1由2月份的87.01%提升至12月份的99.63%,V3由94.05%提升至99.83%。
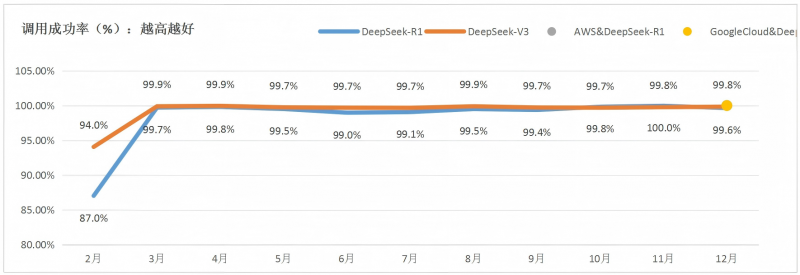
图 11 DeepSeek每月所有平台调用成功率平均值
未来展望:持续优化监测体系推动大模型服务高质效发展
中国信通院表示,未来将持续优化大模型服务监测体系,扩大监测范围,加快监测能力建设,并扩充产业服务能力。在能力建设方面,将优化多模态大模型的监测能力,增加国内外各类最新大模型服务能力的监测;在产业服务方面,将构建大模型服务监测结果展示平台,为企业提供定制化的大模型服务性能指标测试和分析服务。
此次监测结果的发布,不仅为行业用户提供了科学、系统、客观的大模型服务性能评估依据,也为推动大模型技术的普及和应用奠定了坚实基础。由于当前报告覆盖国内外MaaS平台和模型服务数量有限,监测数据仅供行业参考,报告整理可能存在疏漏之处,对该报告的任何问题欢迎与我们沟通交流,后续将结合最新数据持续更新完善。
中国信通院将继续携手产业界各方力量,共同推动大模型服务向更高质量、更高效率的方向发展。
附:监测说明
1.本监测结果仅供参考,由于监测频率、监测时长等维度的限制,监测结果并不能作为衡量公有云大模型服务性能以及MaaS平台能力的绝对依据。且影响首Token时延(TTFT)和每秒输出Token数(TPS)的因素较多,如模型尺寸、网络时延、用户数量、算力及其调度能力、模型能力等。
2.监测基础大语言模型所使用的数据集来自常见的大语言模型基准测试集,构成固定题库。监测时从题库中随机选择题目,且为了减少请求时命中缓存的情况,为每个题目设置了不同长度的干扰Tokens,请求时将干扰Tokens和题目组合成长中短三种类型的请求。
3.监测方法包括每日监测法、集中监测法和人工监测法:
每日监测法,是指通过每日定点的持续性自动化监测,衡量大模型API服务持续的稳定性,包括首Token时延(TTFT)和每秒输出Token数(TPS)。该方法选择北京、上海、深圳、成都4个云节点,于每日选择不同的5个时间整点,向所有大模型API服务连续发送3次长中短请求,并计算其TTFT和TPS。国外服务器位于硅谷。
集中监测法,是指每周选择一个固定时间段集中开展自动化监测,衡量大模型API服务的调用成功率。该方法选择北京云节点,于每周一个固定的时间段,同时向所有大模型API连续发送长中短共300次请求,记录请求成功与否。
人工监测法,是指通过人工对各平台披露的大模型API服务的输入输出价格、每分钟请求数(RPM)和每分钟可处理的Token数(TPM)等信息进行统计更新。
4.每秒输出Token数(TPS)计算公式如下。
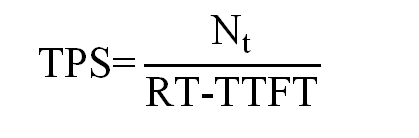
式中:
——输出的Token总数;
——从请求开始到返回完全部Token之间的时延。
5.模型价格归一化计算公式如下。
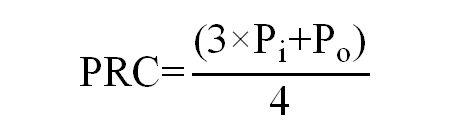
式中:
——每百万输入Tokens的价格;
——每百万输出Tokens的价格。
6.所有大模型API服务的调用统一采用流式输出,其余设置均采用默认值。





